Goals of the root cause analysis of the incidents that have occurred
Before we started with the root cause analysis, we asked ourselves once again what exactly we wanted to achieve by carrying out the RCA. To do this, we took another look at the initial situation: Around a month after the productive release of a major project, first one and then several critical software errors were discovered by the customer and reported to us.
We asked ourselves the following questions and wanted to answer them:
What factors led to Apps with love delivering a non-functioning software increment?
What can Apps with love improve in the long term to prevent such an incident?
Can we reduce the risk for us as a company in the long term through root cause analysis?
Procedure and instructions for carrying out a root cause analysis
So how did we go about carrying out the root cause analysis in our example?
Step 1: Decision to carry out the RCA. A joint decision was made to carry out an RCA with the aim of continuously improving the organization and establishing unusual methods for improvement. The RCA project team and the assignment were defined.
Step 2: Defining the RCA project remit. It was important to define the project remit for carrying out the RCA, set clear objectives, set a time frame, differentiate it from other projects running at the same time and carry out the RCA as independently as possible. The team and the protagonists, the tools and instruments for analyzing and the method to be used were defined.
Step 3: Development of the data basis and chronological documentation of all information. Step 3 was the most time-consuming step, but also the most important. All data had to be documented for further analysis.
So here's what we did:
The reappraisal helped us to isolate and delimit the problems.
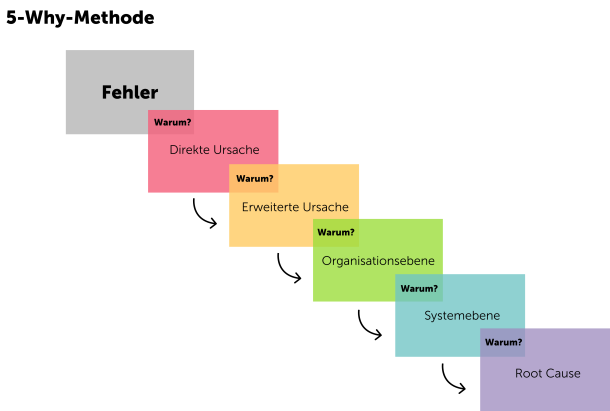
Step 4: Conducting workshops with individual protagonists of the project and jointly analyzing the causes using the 5 Why method. In step 3, we were able to categorize the problems thanks to the detailed data base. This was the basis for the workshops with the individual protagonists. The 5 Why method is used to go through the localized problems individually and describe and document the causes from the perspective of the protagonists at a meta-level. It's important to note that the 5 Why method doesn't say that the cause is clear after the fifth "Why?". It may well be that 7 or more "Why?" questions are needed.
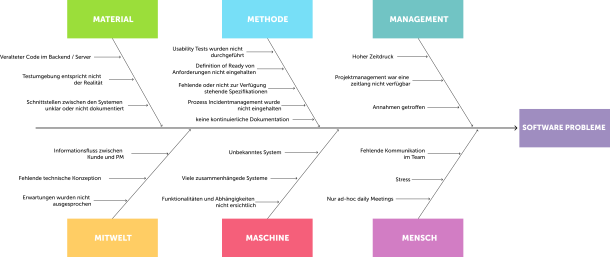
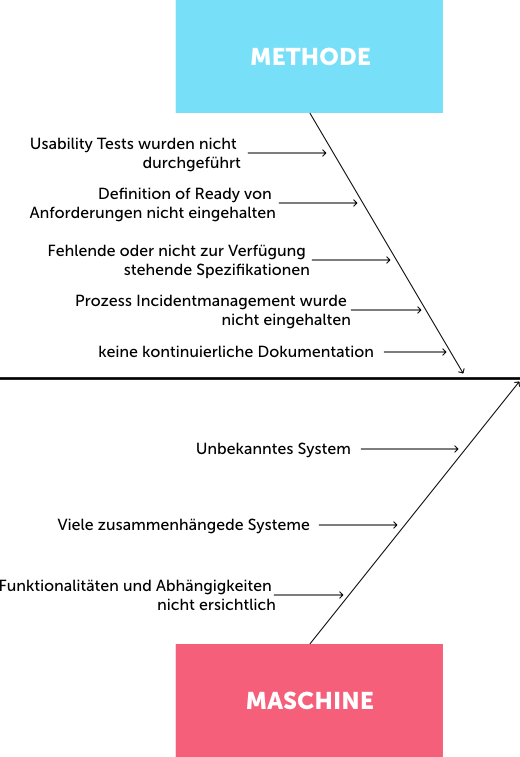
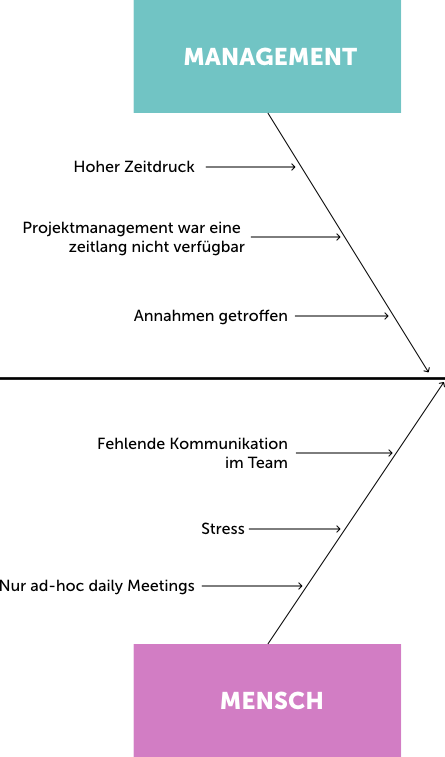
Step 5: Clustering all causes using the fishbone diagram. After the workshops with the protagonists, the causes could be clustered at the meta level and visualized using the fishbone diagram in order to obtain a holistic overview of the causes that contributed to the events.
Step 6: Deriving recommendations and possible measures for improvement. In the next step, the first recommendations and measures could be formulated from the documentation of the 5-Why workshops, the recognized causes and the visual representation of these. It was exciting to see that the first measures were already initiated and tackled by the project team during the implementation of an RCA, before the RCA was actually finalized. Something that seems to happen more often when RCAs are carried out.
Step 7: Presentation of the measures to the project team and then to the individual specialist departments. An important part of the RCA is the presentation of the recommendations and possible measures to the individual specialist departments and teams and their handover for further processing by them.
Step 8: Review implementation of recommendations and measures. It's important to review the implementation of recommendations and measures at regular intervals, enquire about the status and continuously document solutions for improvement. Processes are very often improved and adapted based on the recommendations of an RCA.